vLLM x Novita AI: PegaFlow for Production-Grade External KV Cache
TL;DR: In collaboration with Novita AI, PegaFlow integrates with vLLM as an external KV cache service for LLM inference, implemented as a standalone Rust process and connected through the external KV connector interface. It moves KV cache lifetime out of the vLLM worker process, pools cache across local instances and remote nodes, and combines pinned host memory, RDMA-accessible remote memory, and SSD into a three-level cache hierarchy.
In production-oriented evaluations, this design delivered:
- 2.15x faster vLLM startup when a 500 GiB host KV pool was already owned by the external cache service.
- 56% higher throughput for eight Qwen3-8B instances sharing one host cache instead of eight isolated caches.
- 72% higher throughput for DeepSeek-V3.2 MLA with TP8 by storing logical KV once instead of once per TP rank.
- 194 GB/s average remote-read throughput for large prefix pulls in an internal RDMA cluster with 8 x 400 Gbps NICs per node.
The core idea is simple: KV cache should be a long-lived serving asset, not temporary state tied to one inference process.
For vLLM users, the important part is that this integration is exposed through the existing kv_transfer_config path. PegaFlow can be used as an external cache backend without modifying vLLM source code or carrying a long-lived fork.
Why KV cache needs a process boundary
KV cache is one of the most expensive runtime assets in production LLM serving. It can occupy hundreds of GiB per host, takes time to allocate and warm, and often outlives the request pattern that originally created it.
In a conventional in-process design, that asset is tightly coupled to the inference engine process. This coupling becomes painful during engine crashes, rolling upgrades, and model switches. When an engine restarts, the host KV pool disappears with it. When a serving fleet switches from one model deployment to another, hundreds of GiB of pinned memory may need to be reallocated and warmed before the instance can serve traffic again.
PegaFlow addresses this by moving the KV cache runtime into a standalone daemon on each machine. The PegaFlow server owns the host KV pool, SSD cache, topology metadata, RDMA resources, indexing state, and background tasks. vLLM workers connect to the local PegaFlow process through CUDA IPC on the data path and gRPC on the local control path.
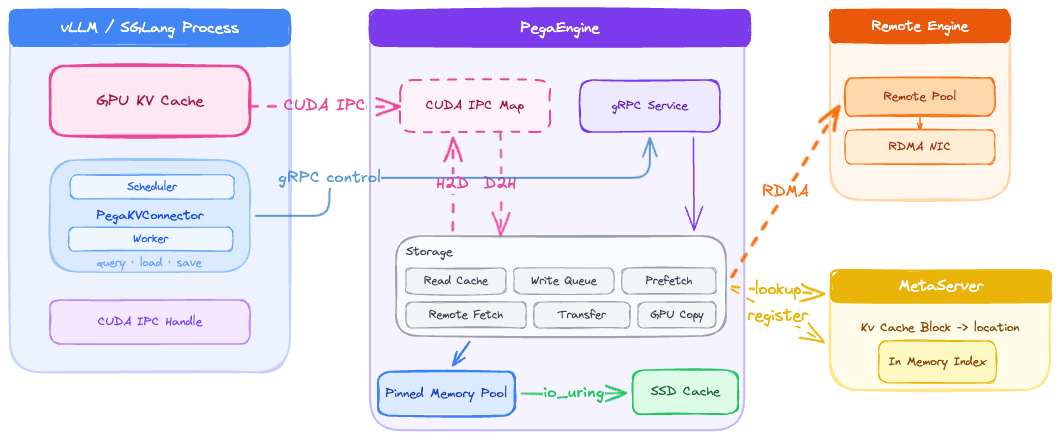
Figure 1: PegaFlow runs as an external KV cache service next to vLLM. vLLM workers communicate with the local PegaFlow server through CUDA IPC and gRPC, while PegaFlow manages pinned memory, SSD cache, RDMA transfer, and optional cross-node indexing through the MetaServer.
This design was built around a production requirement: one cache server should be able to serve multiple engines and multiple models on the same host. Different models, tensor-parallel configurations, and engine versions can coexist under one PegaFlow process with namespace isolation, while sharing the same memory pool, SSD capacity, and cross-node network bandwidth.
The resulting failure domains are cleaner. A vLLM process can crash, upgrade, or switch models while the cache service remains alive. Conversely, cache-layer issues do not have to bring down the inference engine process.
Faster restarts with external cache ownership
To isolate the startup-path impact of host KV pool ownership, we measured an 8 x RTX 5090 setup running Qwen3-8B with TP8. The experiment used dummy weights and eager mode to remove weight-loading and compilation effects, focusing only on the effect of a roughly 500 GiB host KV pool.
With an embedded KV cache design, the 500 GiB pool is owned by vLLM workers, and vLLM took 71.4 seconds to reach ready state.
With PegaFlow, the 500 GiB pool was pre-owned by the standalone PegaFlow server. After the server was ready, vLLM reached ready state in 33.2 seconds. That is a 2.15x faster vLLM startup path for this setup, driven by decoupling long-lived host cache allocation from the inference process lifecycle.

Figure 2: vLLM startup time with a 500 GiB host KV pool. Keeping the pool in the external PegaFlow server cuts the vLLM startup path from 71.4 seconds to 33.2 seconds in this setup.
Rust data path and tail-latency stability
Moving KV cache into an external process was primarily motivated by lifecycle management, sharing, and CPU resource isolation. Implementing that process in Rust also brought an important operational benefit: latency stability.
PegaFlow’s data plane avoids Python interpreter overhead, GIL contention, and stop-the-world garbage collection. This matters because a production cache service does more than move bytes on the critical path. It also runs background tasks such as statistics collection, index uploads, prefetching, health checks, metrics reporting, eviction, and SSD cache management.
In PegaFlow, those tasks run in the same standalone Rust service without sharing an interpreter runtime with vLLM. This gives the system more room to run control-plane and maintenance work without disturbing the data-plane path.
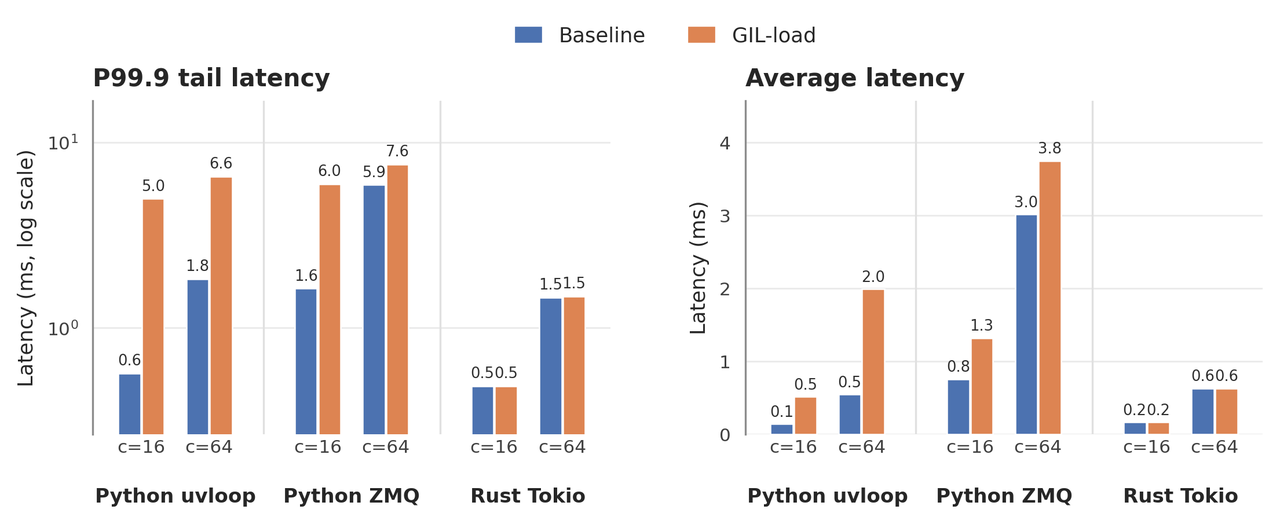
Figure 3: Tail and average latency comparison under baseline and GIL-load conditions. The Rust Tokio path is much less affected by background load than the Python uvloop and Python ZMQ baselines.
Pooling cache across instances and nodes
In production deployments, the same logical KV content is often replicated many times because process, model, or node boundaries make caches invisible to each other.
The pattern shows up in several common deployments:
- Multiple small-model instances on one host. Running eight Qwen3-8B instances on an 8-GPU host can store the same system prompt eight times.
- Wide expert-parallel deployments. Multiple data-parallel replicas on the same machine maintain separate prefix caches even though they run on the same physical host.
- MLA with tensor parallelism. For models such as DeepSeek-V3.2, the logical latent KV can be stored once, but an in-process TP8 deployment may physically store it once per rank.
- Cross-node scheduling. A request may have a cache hit on Node A, but if Node A is overloaded and the request is routed to Node B, the prefix may be recomputed from scratch.
PegaFlow turns these isolated cache fragments into a shared cache pool.
On a single host, all local instances connect to the same PegaFlow server and share one CPU KV pool. For multi-instance small-model serving, WideEP data-parallel replicas, and TP workers, identical blocks can be stored once physically and reused by multiple engines.
Across hosts, a PegaFlow MetaServer maintains an approximate global index. Nodes can fetch remote KV blocks through one-sided RDMA READs, with zero CPU involvement on the remote side after connection setup. A remote hit can therefore be used much more like a local hit, avoiding expensive prefill recomputation.
Results
The following experiments keep the cache budget fixed and change only how visible that cache is across vLLM processes, tensor-parallel ranks, or nodes.
Single-node multi-instance sharing
We evaluated eight Qwen3-8B instances on one host with the same 500 GiB cache budget.
| Setup | Cache layout | Throughput | Mean TTFT | Request hit rate |
|---|---|---|---|---|
| PegaFlow | 500 GiB shared pool | 11.97 req/s | 5.26 s | 52.35% |
| In-process | 8 x 62.5 GiB isolated pools | 7.68 req/s | 8.22 s | 11.77% |
The important point is not that the system used more memory. It did not. The same 500 GiB budget became more useful because requests could draw from one shared pool instead of eight isolated pools. Throughput improved by 56%, mean TTFT dropped by 36%, and request hit rate increased by 4.4x.
MLA logical KV deduplication
We also evaluated DeepSeek-V3.2 MLA with TP8 under a 500 GiB cache budget.
| Setup | Cache layout | Throughput | Mean TTFT | Request hit rate |
|---|---|---|---|---|
| PegaFlow | Logical KV stored once | 1.81 req/s | 35.66 s | 97.23% |
| In-process | KV stored per TP rank | 1.05 req/s | 60.88 s | 65.18% |
For this workload, avoiding repeated storage across TP ranks effectively expanded usable cache capacity. Throughput improved by 72%, mean TTFT dropped by 41%, and request hit rate approached the practical upper bound for the trace.

Figure 4: Summary of the two fixed-budget local sharing experiments. In both cases, PegaFlow improves effective cache capacity by making the same KV budget visible across isolation boundaries.
Cross-node RDMA sharing
In an internal production inference cluster equipped with 8 x 400 Gbps RDMA NICs per node, we sampled thousands of recent online remote reads. For large prefix pulls of at least 1 GiB, PegaFlow sustained 194 GB/s average effective throughput under production traffic, with 250 GB/s P99 and a peak of 261.6 GB/s.
At this transfer rate, a 24 GiB KV cache segment can be pulled from a remote node in roughly 100 ms. That can replace a prefill computation that would otherwise consume seconds of GPU time. In practice, this is what makes remote hits valuable: they are not merely “better than a miss”; they can be fast enough to act like part of the serving path.

Figure 5: Effective throughput for large remote KV cache reads in an internal production cluster. At the measured average throughput, a 24 GiB remote KV segment can be fetched in roughly 100 ms.
Three-level cache hierarchy
Pooling makes cache capacity more useful, but host memory is still finite. Long reuse-distance prefixes may be evicted before their next use, and simple LRU can be heavily disrupted by scan-like traffic where many one-time blocks pass through the system.
PegaFlow addresses this with a three-level cache hierarchy. Hot local blocks stay in pinned DRAM, remote hits can be fetched over RDMA, and colder reusable blocks can spill to local SSD:
| Level | Medium | Access path | Typical role |
|---|---|---|---|
| L1 | Local pinned DRAM | Local memory | Fast local KV reuse |
| L2 | Remote DRAM | RDMA READ | Cross-node cache sharing |
| L3 | Local SSD | io_uring | Large-capacity spillover |
The SSD cache is implemented in Rust on top of io_uring. In internal tests, a single SSD delivered roughly 6.9 GB/s peak read throughput. PegaFlow keeps online steady-state throughput around 6.5-6.6 GB/s per disk, trading about 5% peak bandwidth for more stable tail latency. With RAID0 across multiple disks, total throughput scales approximately linearly.
For scan-heavy workloads or hosts with smaller cache budgets, PegaFlow can enable a TinyLFU admission policy. This policy admits blocks only when they are likely to be reused, protecting the cache from one-time traffic.
TinyLFU is disabled by default because the best admission policy depends on workload shape. In several internal traces, however, it substantially outperformed LRU when the cache was small or scan pressure was high.
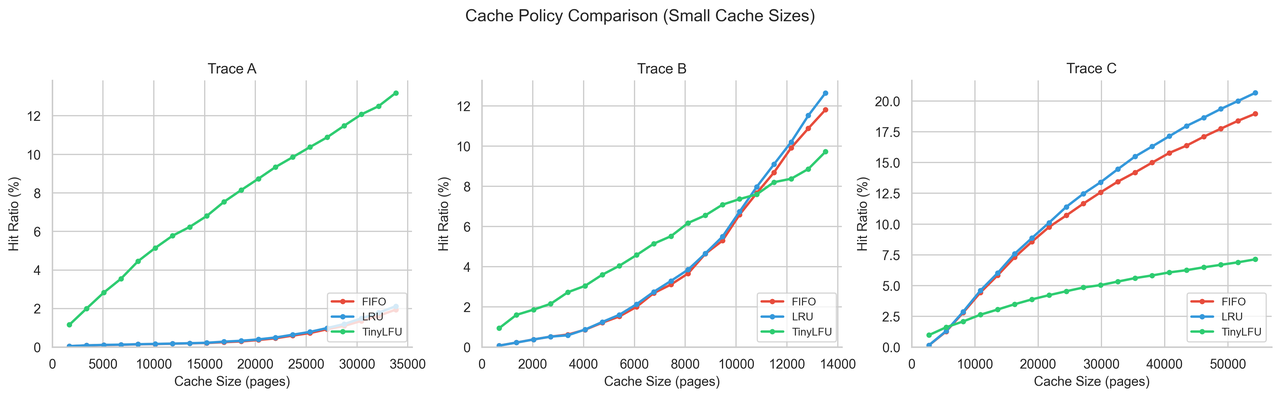
Figure 6: Cache-policy comparison under small cache sizes. Scan-heavy traces can make simple recency-based policies ineffective, while admission-aware policies such as TinyLFU can protect the cache from one-time blocks.
Measuring distance from the theoretical hit-rate ceiling
Online hit rate alone can be misleading. A 3% hit rate may be good for a workload with very little reuse, while a 90% hit rate may still leave significant room if the workload’s theoretical upper bound is much higher.
For operators, the useful question is not just “what is the hit rate?” It is “how close are we to the best hit rate this workload could reasonably achieve?”
PegaFlow estimates the theoretical hit-rate upper bound online using HyperLogLog:
r* = (N - U) / N
Here, N is the total number of block requests in a window, and U is the number of first-seen unique blocks. HyperLogLog keeps this estimate inexpensive: a 24-hour window uses less than 1 MiB of memory with roughly 0.8% error.
PegaFlow exports rolling HLL windows, with defaults of 15 minutes, 1 hour, and 24 hours. By placing measured hit rate and theoretical upper bound on the same dashboard, operators can distinguish three cases:
- The cache is already close to the workload ceiling, so adding capacity may not help much.
- The measured hit rate is far below the ceiling, suggesting room for better capacity, admission, prefetching, or cross-node discovery.
- The theoretical ceiling itself is low, indicating that the workload has limited reuse and the bottleneck is not primarily the cache implementation.
Integrating with vLLM through the external connector
External KV cache systems often require invasive changes to the scheduler, block manager, or attention kernels. PegaFlow instead integrates through vLLM’s external KV connector mechanism.
The connector is configured through kv_transfer_config, and external packages can be loaded dynamically with kv_connector_module_path. This lets PegaFlow take over key KV cache operations at runtime without modifying vLLM source code or carrying a long-lived fork.
From vLLM’s perspective, PegaFlow is not a replacement for the serving engine. It is an external cache backend attached through the KV transfer interface, while vLLM continues to handle scheduling, model execution, batching, and the OpenAI-compatible serving path.
This boundary is useful for both projects. PegaFlow can iterate on its Rust data plane, SSD cache, RDMA path, indexing, and connector logic independently. vLLM can continue improving the core serving engine while exposing a stable connector contract for external cache systems.
Quick start
Install the package for your CUDA version:
uv pip install pegaflow-llm # CUDA 12
uv pip install pegaflow-llm-cu13 # CUDA 13
Start a single-node PegaFlow server with pinned host memory and SSD cache:
pegaflow-server \
--pool-size 30gb \
--ssd-cache-path <ssd-cache-file-path> \
--ssd-cache-capacity 512gb
For online deployments, we recommend adding --use-hugepages. Huge pages should be reserved in advance. They speed up CPU pinned-memory allocation and reduce RDMA MTT pressure by lowering address-translation overhead during registration and transfer.
For multi-node deployments, start the MetaServer first, then start a PegaFlow server on each node with RDMA configuration. When P2P is enabled, each PegaFlow server’s --addr must be a routable IP address, not 0.0.0.0 or 127.0.0.1, because other nodes use it for the gRPC handshake and block queries.
pegaflow-metaserver --addr 0.0.0.0:50056
pegaflow-server \
--addr this-node:50055 \
--pool-size 30gb \
--ssd-cache-path <ssd-cache-file-path> \
--nics mlx5_0 mlx5_1 \
--metaserver-addr http://metaserver-host:50056
Connect vLLM without modifying vLLM source code. The examples in this post use vllm>=0.20.0:
vllm serve <model> \
--kv-transfer-config '{
"kv_connector": "PegaKVConnector",
"kv_role": "kv_both",
"kv_connector_module_path": "pegaflow.connector"
}'
The PEGAFLOW_HOST and PEGAFLOW_PORT environment variables point the connector to the PegaFlow service. By default, they are http://127.0.0.1 and 50055.
Public reference benchmark
The PegaFlow repository also includes a public KV cache benchmark on H800 with Llama-3.1-8B, using 8 prompts, 10K-token prefill, 1-token decode, and 4.0 req/s. In that setup, the warm cache path reduces mean TTFT from 572.5 ms to 61.5 ms, with P99 TTFT dropping from 1113.7 ms to 77.0 ms.
Try PegaFlow
PegaFlow is available on GitHub: novitalabs/pegaflow. The repository includes installation instructions, server configuration, P2P RDMA setup, metrics documentation, and vLLM connector examples.
Acknowledgements
We would like to thank the Novita AI team for building and productionizing PegaFlow, and the vLLM maintainers and broader vLLM community for the discussions, reviews, and connector infrastructure that made this integration possible.